CMSIS库以及相关算法
CMSIS库
概介
CMSIS 全称是 Cortex Microcontroller Software Interface Standard。
它的目标是统一 Cortex-M 平台上的底层接口、驱动抽象和高性能算法库,方便你在不同芯片厂商之间移植代码。
它主要包含这些部分:
- CMSIS-Core:Cortex-M 内核寄存器、NVIC、中断、SysTick 等底层访问接口
- CMSIS-DSP:数字信号处理库
- CMSIS-NN:面向 Cortex-M 的神经网络推理内核
- CMSIS-RTOS:RTOS 抽象接口
- CMSIS-Driver:外设驱动统一接口
- CMSIS-Pack:软件包管理和工程集成规范
对于本项目方向,核心关注点是:
- 信号预处理用 CMSIS-DSP
- 神经网络推理用 CMSIS-NN
CMSIS库的优势
光谱处理的本质就是信号处理,预处理流程通常包括基线矫正,归一化,数据处理阶段包括去噪,平滑,FFT,特征提取,这些均在CMSIS-DSP库内有封装的函数
之后把处理后的特征送入轻量级嵌入式设备模型,再用CMSIS-NN推理
其优势:
- 针对Cortex-M做过优化(n6使用M55),速度和功耗优于自定义函数
- 支持定点运算,适合无FPU的设备
- 能和TensorFlow for Microcontroller适配
CMSIS-DSP
包括:
1 | |
CMSIS-NN
一组神经网路算子加速库,不是训练框架,主要用于在MCU上高效执行推理,适合
- 1D CNN
- 小型全连接网络
- 关键词识别
- 传感器分类
- 时序/频谱特征分类
它常见支持的算子包括:
- 卷积
- 深度可分离卷积
- 全连接层
- 激活函数
- 池化
- Softmax
CMSIS-DSP 算法
FIR平滑滤波
FIR平滑滤波的原理及其朴素,本质公式如下
$$y[n] = \sum_{k = 0}^{M-1} h[k]x[n-k] $$
x为输入,y为输出,h为FIR滤波器系数,M为滤波器长度
数学含义就是此处的输出为最近M个点的加权平均
若$$ h[k] = \frac{1}{M}$$
就是最简单的滑动平均滤波器
关于为什么能去噪的原因很简单:方差计算的结果为原来的根号M分之一
在频域内,FIR滤波器是低通滤波器
缺点:降低分辨率,有一定的延迟($$\frac{M-1}{2}$$次采样)
SG滤波
SG滤波:光谱处理内的经典滤波算法,具有保留原信号的形状的能力
本质:基于局部多项式回归的数字滤波器,核心是通过线性最小二乘法将低阶多项式集合到相邻数据点的滑动窗口中,能在降低噪声的同时保持信号的高阶矩,意味着信号的峰值谷值可以得到较好的保持
滤波器的工作过程:在信号序列上滑动固定大小的窗口,对窗口的数据点进行多项式拟合,窗口大小和多项式阶数是该算法的两个关键参数,算法在每个窗口位置内计算多项式在中心的值,作为输出
下面详细介绍数学原理:
多项式拟合:SG滤波器的核心就是局部多项式拟合,设$$(x_i,y_i)$$,i为不含0的自然数,目标是用p阶多项式对局部数据进行拟合
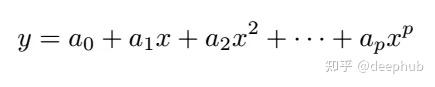
对于中心位于$$x_k$$需要确定向量$$[a_0,a_1…a_p]$$使得多项式能够最佳拟合窗口内的数据点,此优化问题通过最小化均方误差来解决
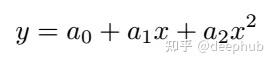
为了说明算法的具体实现过程,我们考虑一个简单的例子:窗口大小为5(即m=2)的2阶多项式拟合,数据点为:
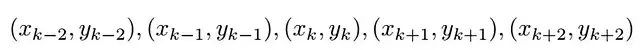
二阶多项式进行拟合
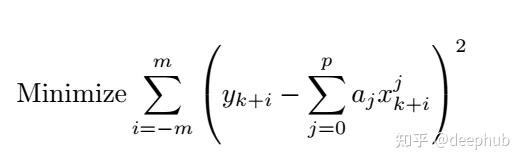
一系列的工程分析不予展示,这里给出关于不同窗口和阶数对于去噪效果的影响
- 小窗口低阶配置:能够保持局部特征,但对高频噪声的抑制效果有限
- 小窗口高阶配置:可以捕获复杂的局部变化,但存在过拟合风险
- 大窗口低阶配置:具有良好的噪声抑制效果,但可能会过度平滑信号特征
- 大窗口高阶配置:在保持信号特征的同时提供平滑效果,但需要注意窗口大小与信号特征尺度的匹配
实践指南:
参数选择策略
Savitzky-Golay滤波器的性能很大程度上取决于窗口大小和多项式阶数的选择。这两个参数需要根据具体应用场景进行优化。
窗口大小选择
小窗口:适用于快速变化信号的处理
优势:能够保持信号的局部特征和快速变化
局限:噪声抑制效果可能不够理想大窗口:适用于缓慢变化信号的处理
优势:具有更好的噪声抑制效果
局限:可能会模糊信号的局部特征
多项式阶数选择
低阶多项式(p=2或3)
适用于平滑变化的信号
具有较好的抗噪声能力
计算效率较高高阶多项式(p=4或5)
适用于具有复杂局部结构的信号
能够更好地保持信号特征
需要注意过拟合风险
算法局限性
边界效应
注意:这并不是DSP库内封装函数,所以需要离线求得卷积系数在用FIR和卷积实现
基线校正
基线校正是光谱预处理中的关键步骤,用于消除由仪器飘逸,北京散射和荧光效应产生的低频干扰信号,未校正的基线会导致峰位漂移,定量分析误差等问题
基线漂移的来源:
- 探测器温度波动
- 光线的散射
- 非目标物质的干扰信号
- 器件老化
常用基线校正方法
- 多项式拟合法
适用场景:平缓变化的简单基线
关键参数:多项式阶数(通常3-5阶) - 自适应迭代重加权惩罚最小二乘法
通过迭代调整权重矩阵 实现基线拟合
优势:自动适应复杂基线形态
关键参数:平滑因子λ、迭代次数 - 小波变换法
利用小波分解提取低频基线成分
优势:保留高频有用信号
关键参数:小波基函数选择、分解层数
代码实例
1 | |
和SG一样,基线漂移也需要调用CMSIS的函数来实现
幅值校正(归一化)
归一化(Normalization)是一种数据预处理 技术,旨在将不同量纲、不同取值范围的数据转换到相同的尺度上,以便进行更加公平、有效的比较或分析。
Mini-MAX归一化
将数据线性映射到[0,1]范围内
优点:保持数据的比例关系,简单易行,适合有固定上下界的场景
缺点:对极端值很敏感
Z-score归一化
Z-score 归一化通过减去均值再除以标准差,使得数据呈标准正态分布,均值为 0,标准差为 1。其公式为:
优点:不受极端值的影响,适合处理正态分布的数据
缺点:如果不是高斯分布效果较差,不能保证数据在[0,1]之间
最大值归一化:最大值归一化是将数据除以它的绝对最大值,使数据的范围归一化到 [-1, 1] 之间。其公式为:
优点:简单快速,适合在数据分布中心为零时使用
缺点:仍然对极端值敏感
小数定标归一化
小数定标归一化通过将数据除以一个 10 的整数次幂,使归一化后的数据范围在 [-1, 1] 之间。其公式为:
优点:适合当数据范围比较固定且易于计算时使用m
向量归一化
向量归一化通常用于将向量的模长标准化,使整个向量的长度为 1。常用于文本处理、图像处理 等领域。公式为:
其中$$\left | x \right |$$是向量 x 的 欧几里得范数,即
优点:在处理向量(如图像、文本等)的任务中非常有用,可以消除向量长度差异带来的影响
不同归一化方法的应用场景
Min-Max 归一化:常用于数据范围已知,且目标是将数据归一化到固定范围(如 [0, 1])的场景,广泛应用于神经网络等需要定量计算的数据模型中。
Z-score 归一化:适合数据分布为正态分布或需要消除量纲影响的场景,常用于聚类分析和 PCA(主成分分析)等模型。
最大值归一化:适用于数据值围绕中心对称分布,且希望将数据映射到 [-1, 1] 区间的情况,常用于 SVM 等机器学习算法。
小数定标归一化:适合数据的取值范围较大,且位数变化相对固定的场景。
向量归一化:适用于向量数据,如文本分类、图像处理等领域,特别是当要消除向量大小的影响时。
特征增强
- 一阶导
突出变化趋势,适合看斜率变化和峰边界 - 二阶导
更强调曲率和峰结构,常用于分离重叠峰,但更容易放大噪声 - 差分
本质上也是强调相邻点变化 - 峰检测
把有意义的局部极值找出来 - 波段选择
从全谱里挑对任务最有信息量的波段
变换和压缩
- FFT
是把时域/序列信号变到频域,重点是“换表示”。 - DCT
也是变换到另一组基函数空间,常用于能量集中和压缩。 - PCA
是把高维相关变量投影到少数主成分上,重点是降维和保留主要方差。